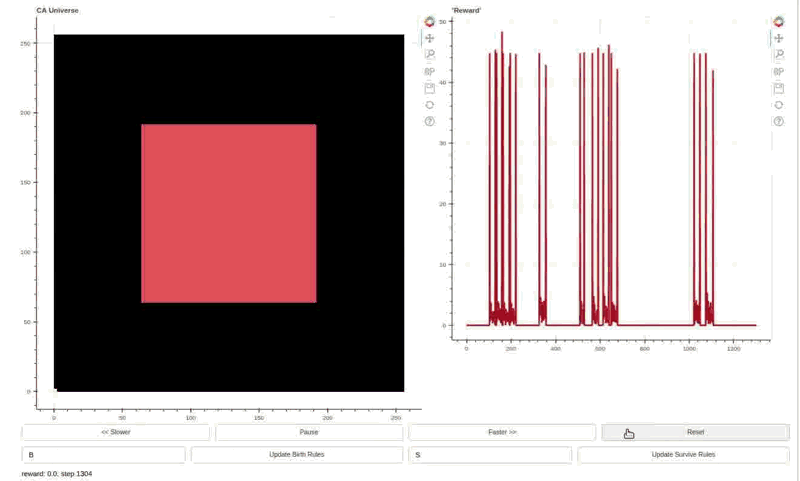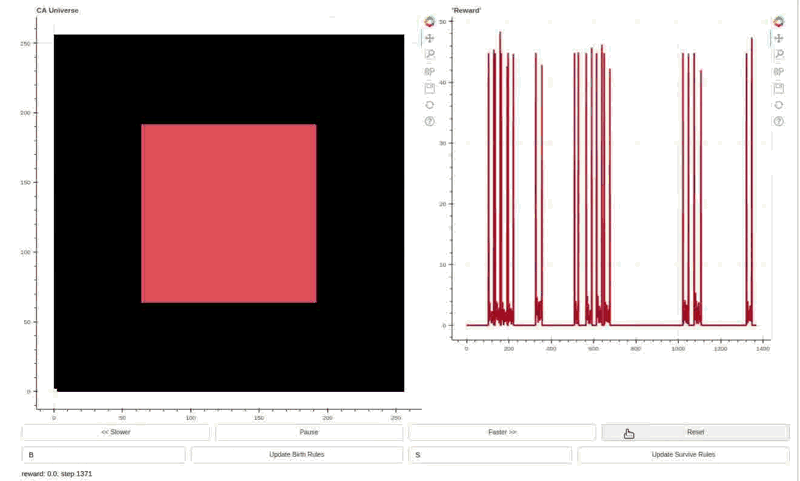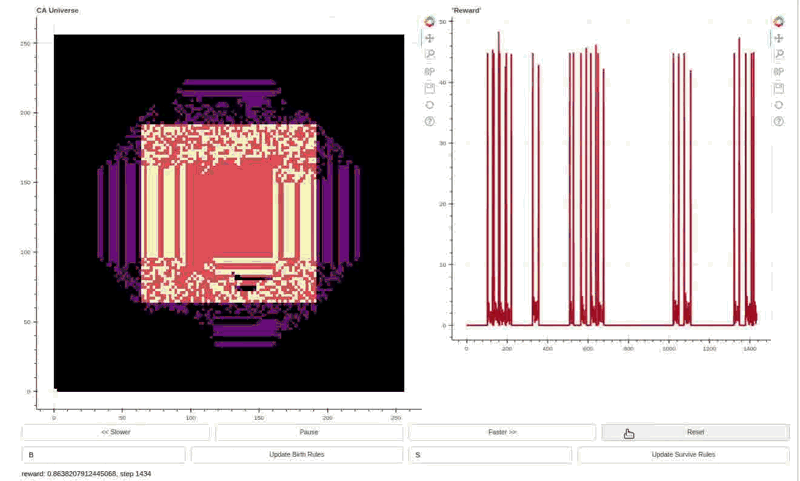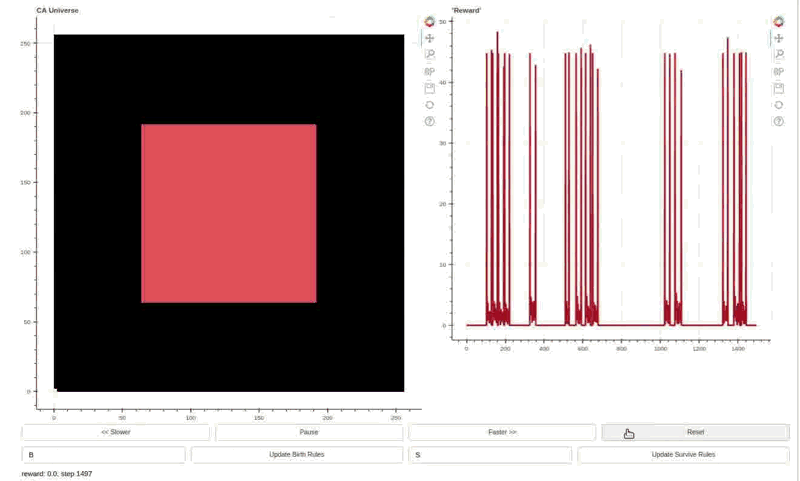
Reward trace on the right and Life-like cellular automata environment on the left. The agent can toggle the cells in the central square area. An objective function rewards changing center of mass outside of the action area cells. This policy has learned to generate high rewards by creating linear waves and resetting the environment by toggling all the action cells at once.
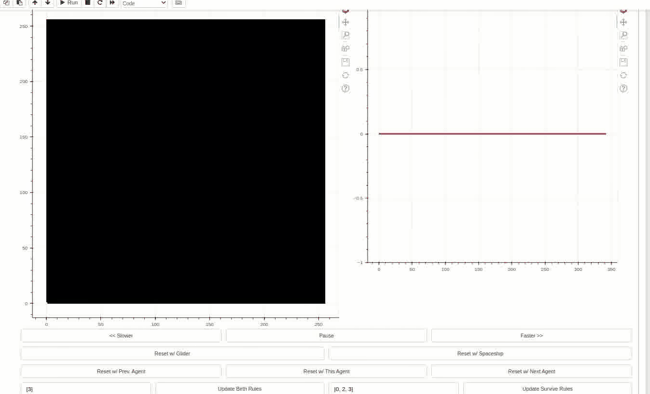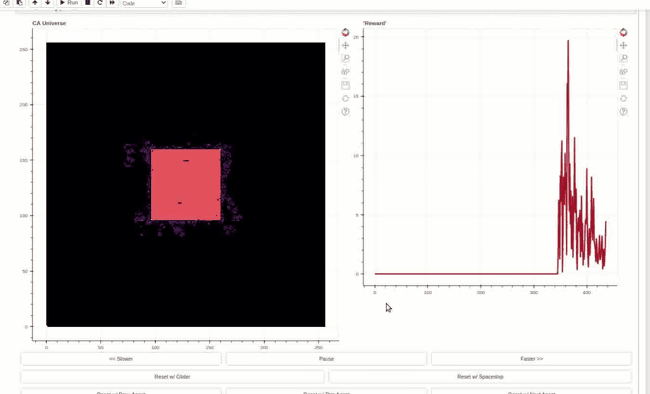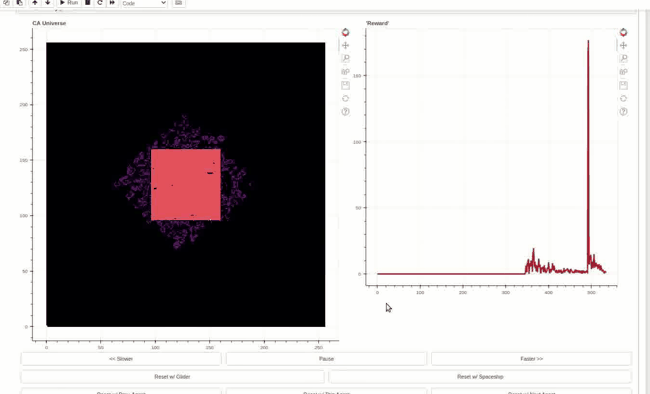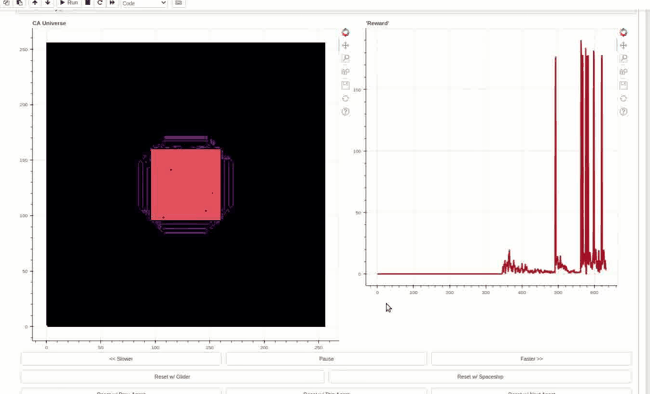
The policy is Hebbian! The weights are initialized randomly, and the evolved Hebbian learning rule eventually finds a way to enact the reward exploit policy. The policy was evolved in Life-like rules B3/S023 (DotLife), B3/S236, B3/S237, and B3/S238. Life itself (B3/S23) was held out as a validation rule set. Although archetypical light/middle weight spaceships do not work in each of the rule sets, the wave+reset policy is effective in generating high rewards in all five rules. The agent policy, dubbed Hebbian Automata Reinforcement Learning Improviser (HARLI), is a neural cellular automata defined by 4 Hebbian parameters per weight.