Update 2021-04-05: Alpha release: support for run-length encoding, stacked reward wrappers, and more.
Update 2021-04-05: Alpha Release
CARLE is now in a state to permit useful experimentation and exploration. Recent additions rolled into the alpha release include:
- Stacking reward wrappers now works, so multiple reward metrics can be applied for simultaneous training(there are 4 included, but experimenters are encourage to implement their own).
- Reward wrappers intended to correlate with the development of puffers/guns and gliders have been added.
- Evaluation functionality and a random baseline demonstrator have been added.
- Support for run-length encoding makes it much easier to import export cellular automaton universes to be used with external tools like Golly.
Also I recently picked up a day job, which will make developing CARLE and running Carle’s Game for IEEE CoG 2021 significantly more challenging. However, I am still of the mind that it’s a doable thing, and my ideas about judging the contest have crystallized somewhat.
Currently evaluation functionality is accomplished by stacking the 4 included reward wrappers around CARLE with certain reward component weighting and accumulating rewards over 1024 steps for 5 different Life-like rulesets (Life, Morley/Move, Day and Night, DotLife, and Live Free or Die)*. However I’ve come to realize that evaluating machine creativity in an open-ended context like Carle’s Game will necessarily by a matter of subjective human judgement for all that entails. I think it would be a mistake to rank one agent that scores higher on arbitrary proxy metrics over another agent that discovers and exciting new puffer pattern. Therefore judging will be a matter of human judgement and quantitative proxy metrics will be used as a tool for human observers to explore agent activity and used to break ties in the event of conflicting or ambiguity.
In order to facilitate human interaction with agents’ exploration in CARLE, the beta release deadline has been moved to April 30th, and the objective has been changed to center around building tools for humans to use to judge agent activity. I plan to use Bokeh for the first iteration of this functionality, but ideally I’ll be able to implement interactive evaluation tools that can be publicly available on GitHub pages, something that looks a little like Life implementations by wangytangy, magicmart or Igor Konovalov. The trick is to convert PyTorch models to a portable representation that can be called from javascript.
Stay tuned for further developments. Meanwhile, here are some of the random baseline evaluation runs, which should make clear the difficulty of relying on proxy reward metrics:
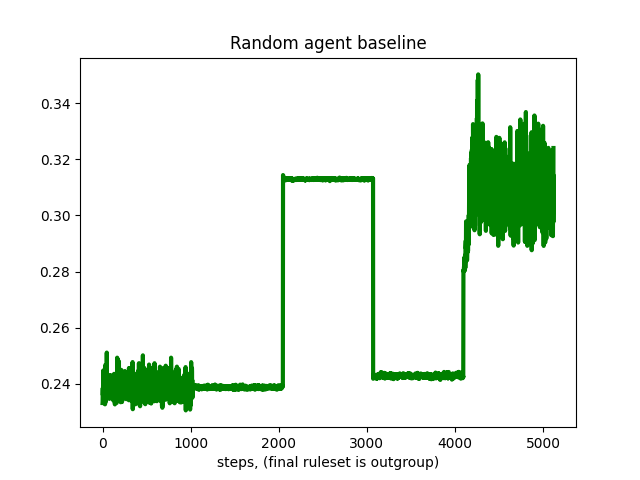
Random baseline 1, mean reward per step over 5120 steps in 5 different rulesets: 2.684e-01
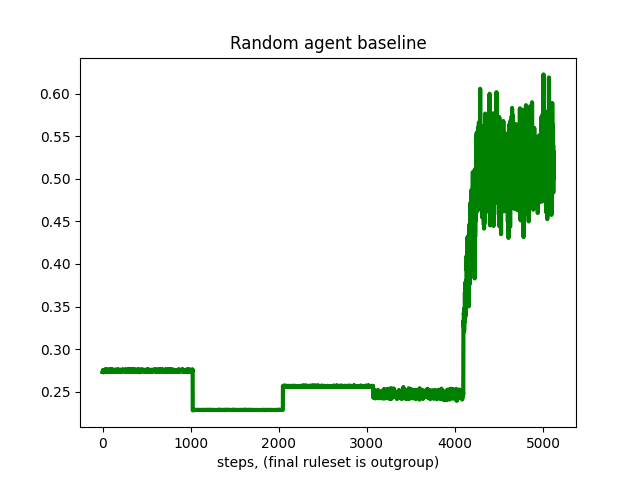
Random baseline 2, mean reward per step over 5120 steps in 5 different rulesets: 3.011e-01
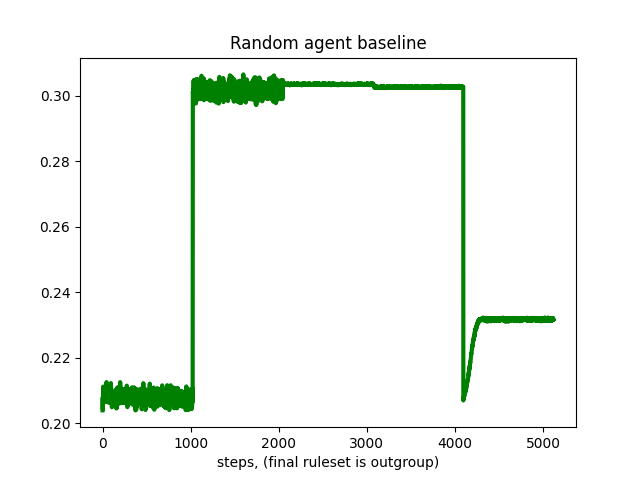
Random baseline 3, mean reward per step over 5120 steps in 5 different rulesets: 2.690e-01
- aka B3/S23, B368/S245, B3678/S34678, B3/S023, and B2/S0