This gh-pages page is deprecated. Check out the Carle’s Game Blog, challenge guidelines, or the example submissions.
An Open-Ended Challenge in Simple Complexity, Exploration, and Machine Creativity
Carle’s Game is an open-ended challenge for creative machine intelligences based on the Cellular Automata Reinforcement Learning Environment (CARLE). CARLE is a flexible, fast environment that supports arbitrary Life-like cellular automata (CA) rule sets.
Environment Description
The details of this description of CARLE may change
CARLE is formulated as a reinforcement learning environment for binary CA grid universes. Although it follows RL patterns, it doesn’t provide a non-zero reward or a done signal signifying the end of an episode. Adding episodic constraints and reward proxies conducive to effective learning is the principle challenge of Carle’s Game.
The action space is 32x32, located in the center of the CA grid universe, and is expected to take binary values of 1 or 0. A 1 action signals to toggle the cell at a given location and an action of 0 signifies no change. The observation space is nominally 64x64 but can be adjusted by changing env.height and env.width, and may be changed in the final training and/or test environments. Observations are provided as Nx1xHxW PyTorch tensors, and actions are expected in the same format. Notably, N can be greater than 1 when training and this allows for many CA universes to be updated in parallel, this is adjusted by changing the env.instances variable.
CA grids represent the surface of a toroid, i.e. the unverse wraps around on itself like Pac-Man. CARLE offers several desirable traits for training creative machines, including open-endedness, flexibility, and speed.
Open-Endedness
While CARLE is formulated as a reinforcement learning environment and uses the the now-standard OpenAI gym pattern (obs, reward, done, info = env.step(action)), done is never returned as True and the environment itself only every returns a reward of 0.0. Users of CARLE are encouraged to develop their own strategies to instill training with a sense of curiosity, planning, play, and anything else that might encourage machine creativity.
As an example, CARLE includes an environment wrapper that implements random network distillation (RND, Burda et al. 2018) as well as autoencoder loss as exploration bonus metrics. The following animations demonstrate RND rewards for a policy that toggles every cell in the action space (“ones” policy) and a random policy that toggles 2% of cells. The demonstrations contrast these policies applied to Conway’s Game of life and “Mouse Maze” CA rule rule sets, which are typically represented by the conditions that lead to cells switching from a 0 to a 1 state (“birth” or “B”) or to persist in a 1 state (“survive” or “S”). The rules for Life and Mouse Maze can be written as B3/S23 and B37/S12345, respectively.
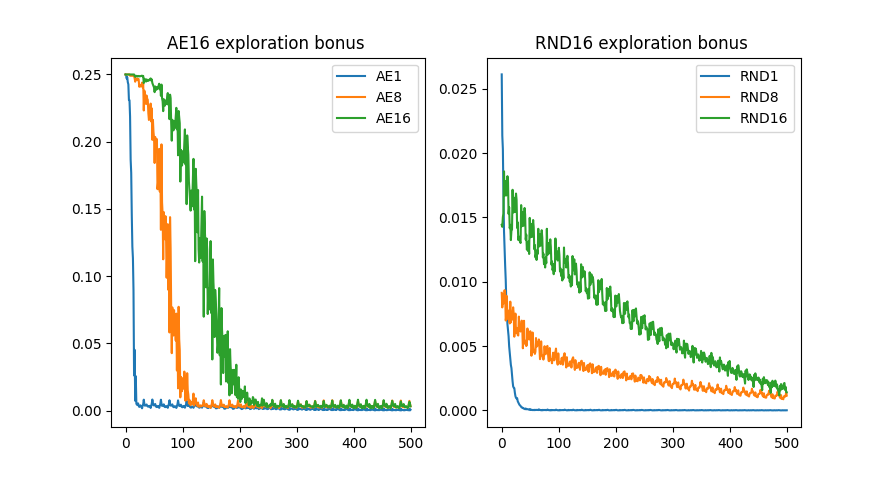
Exploration-based rewards can be implemented as environment wrappers, such as the included autoencoder loss bonus and random network distillation bonus shown here. Batch size can be adjusted to accumulate gradients over `batch_size` number of time steps. Here "AE1", "AE8" etc. refer to the autoencoder bonus applied with a batch size of 1 and 8, respectively, and random network distillation (RND) batch size is denoted using the same pattern.
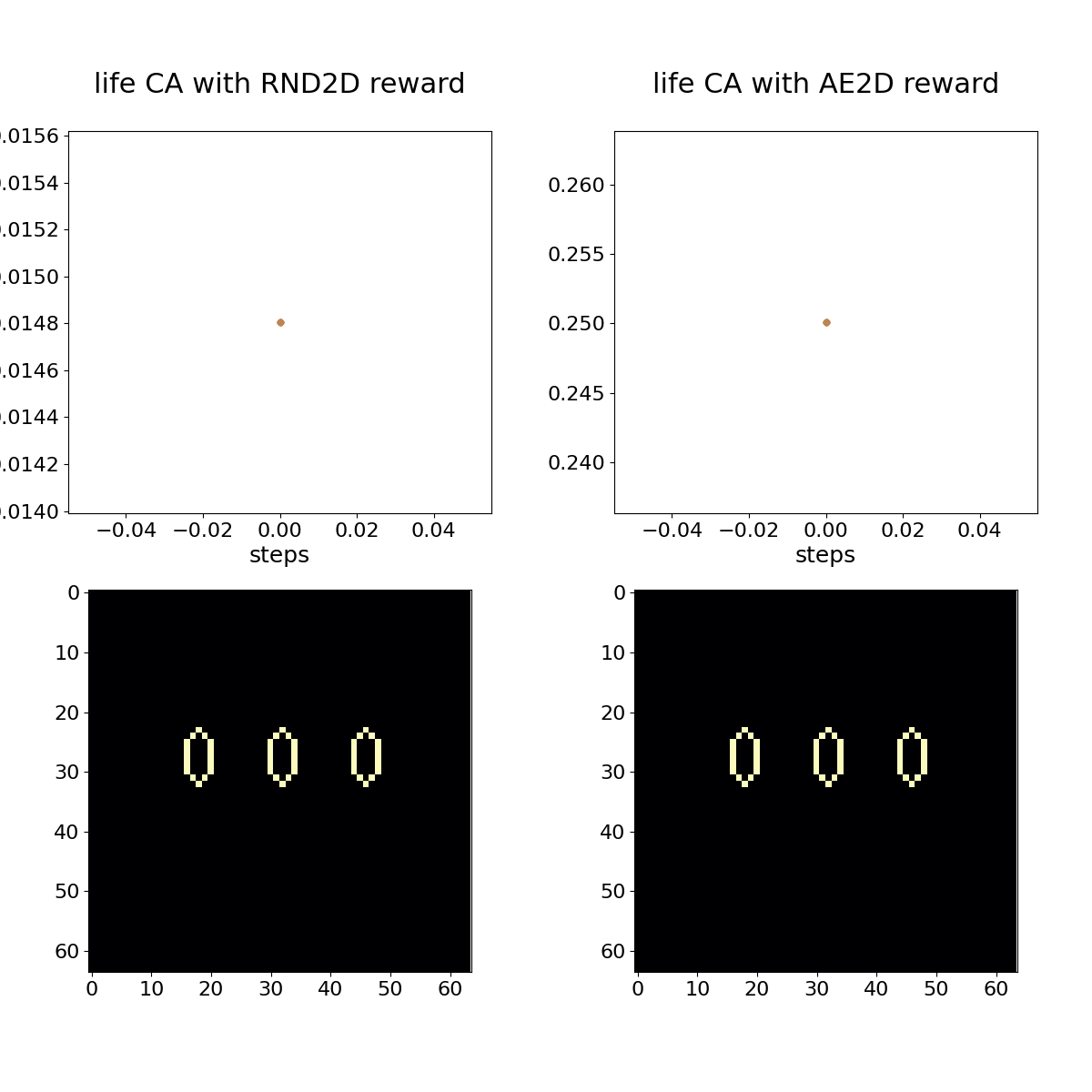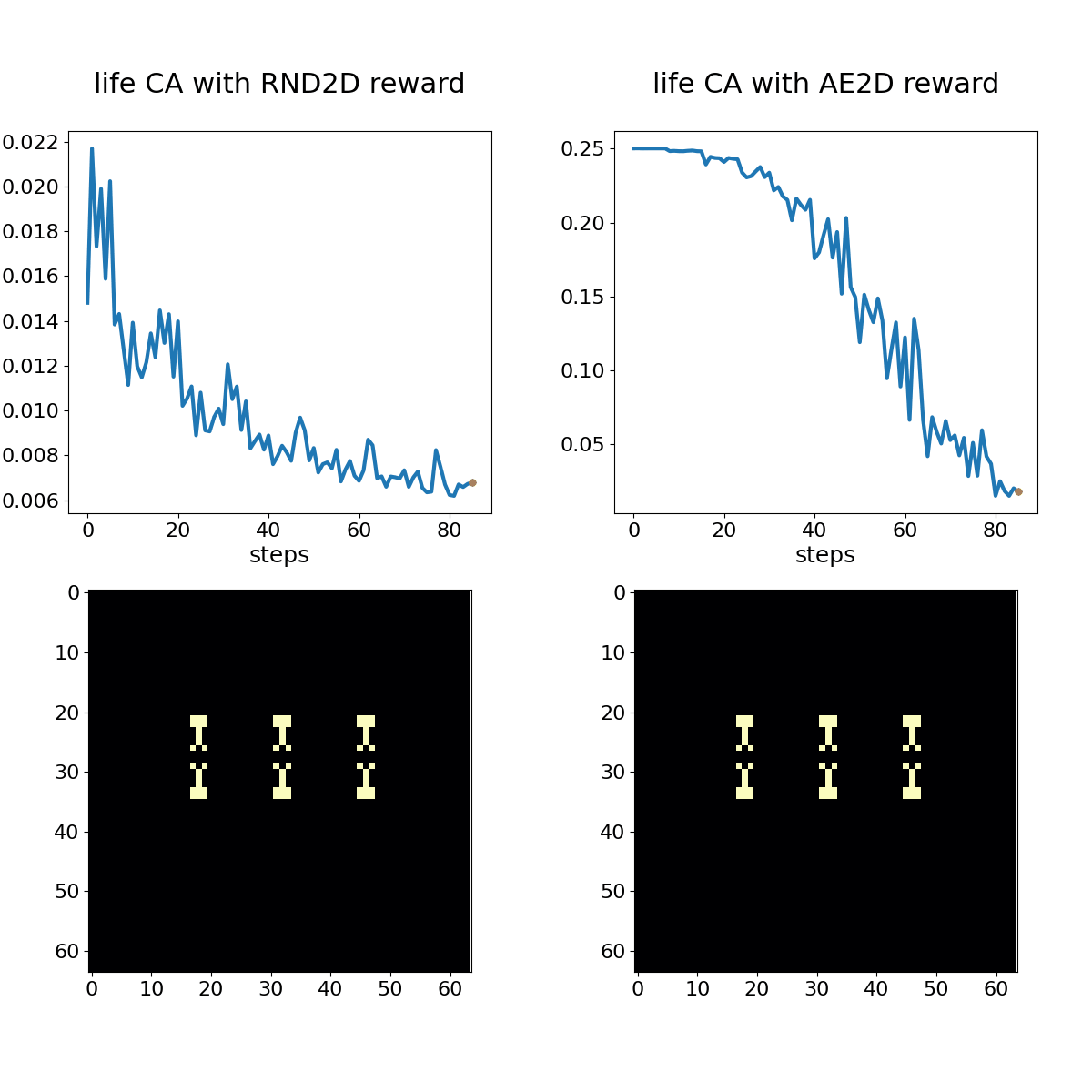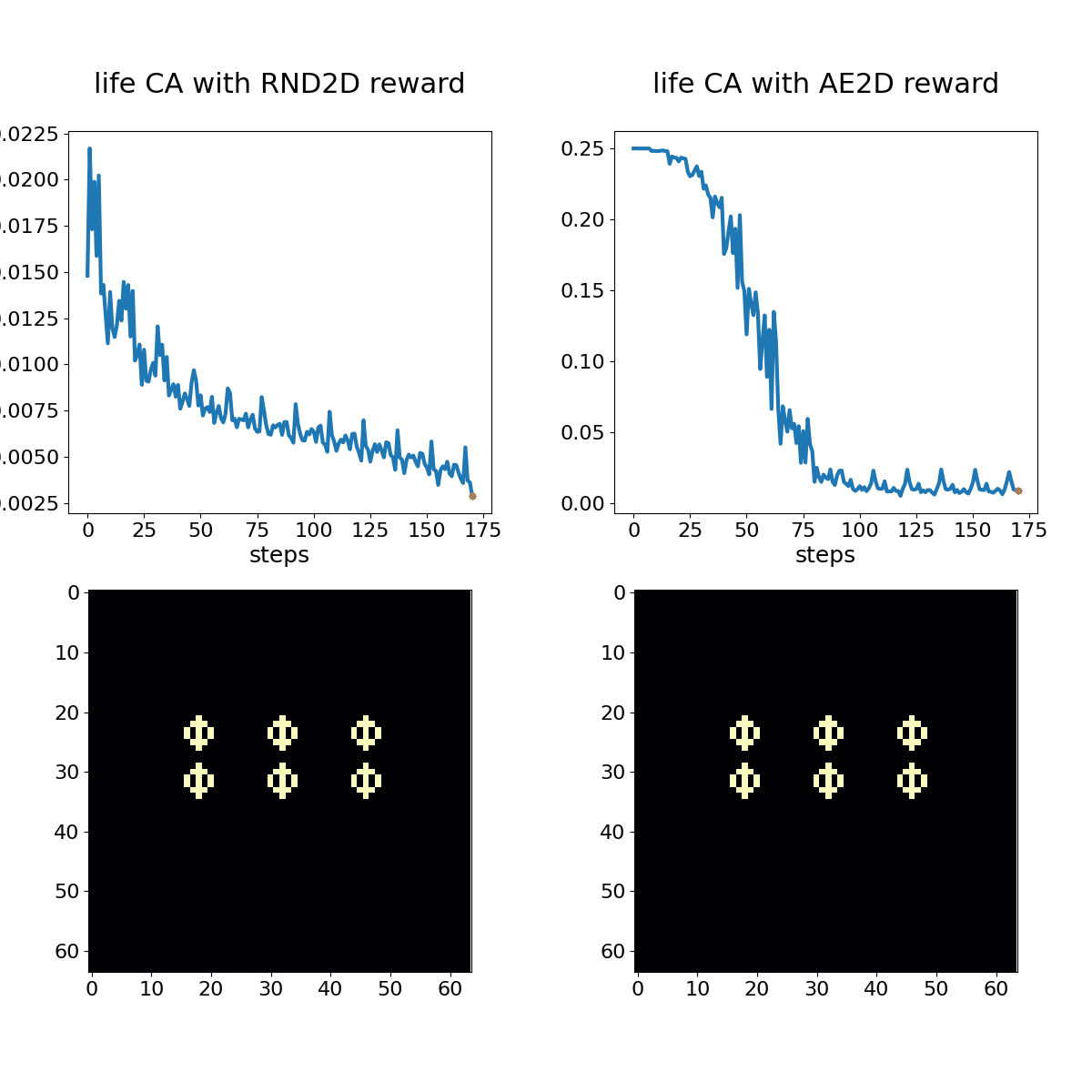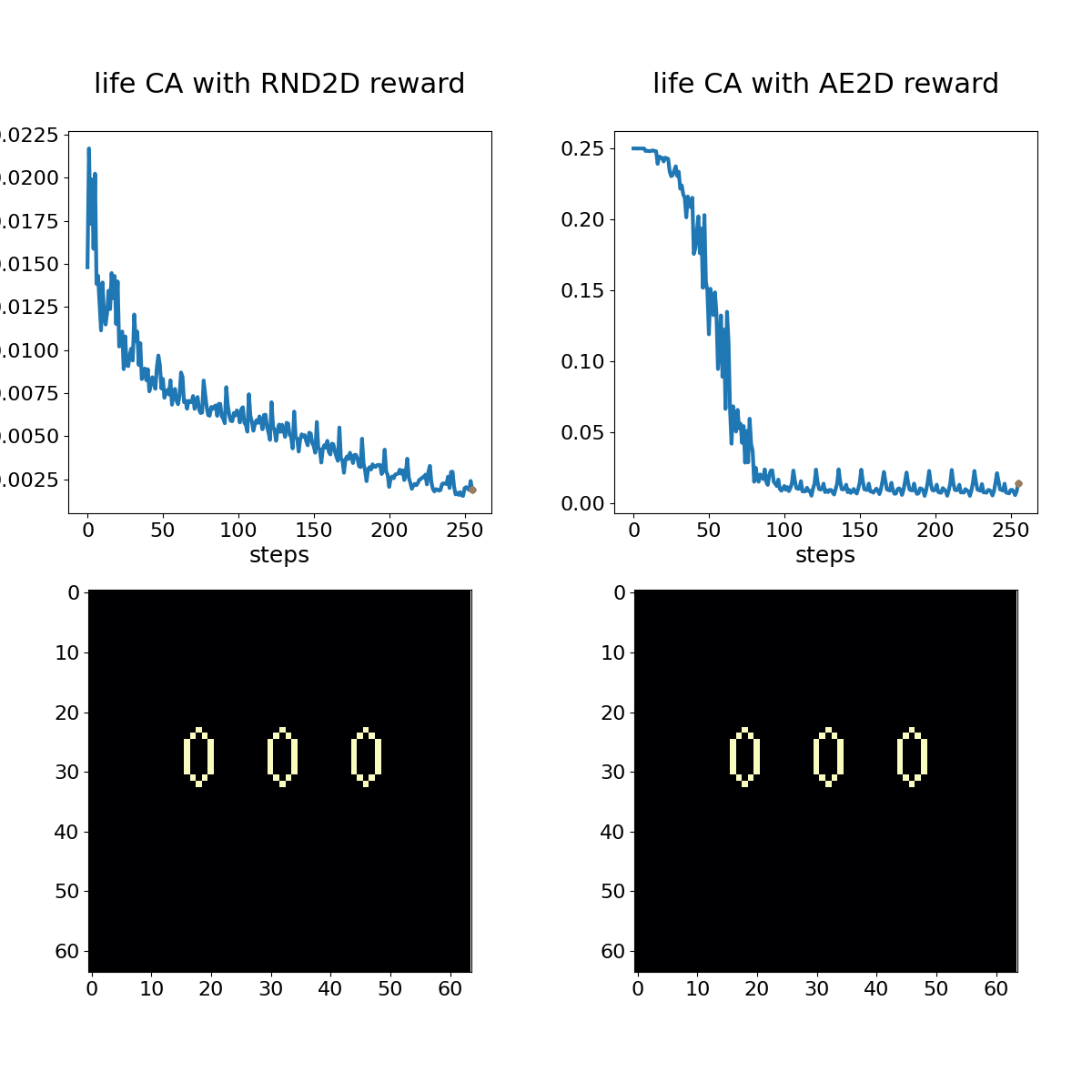
Conway's Game of Life shown with associated RND (left) and autoencoder loss (right) bonuses. The policy in this case is a hand-coded oscillator that is set up on the first time step and left alone.
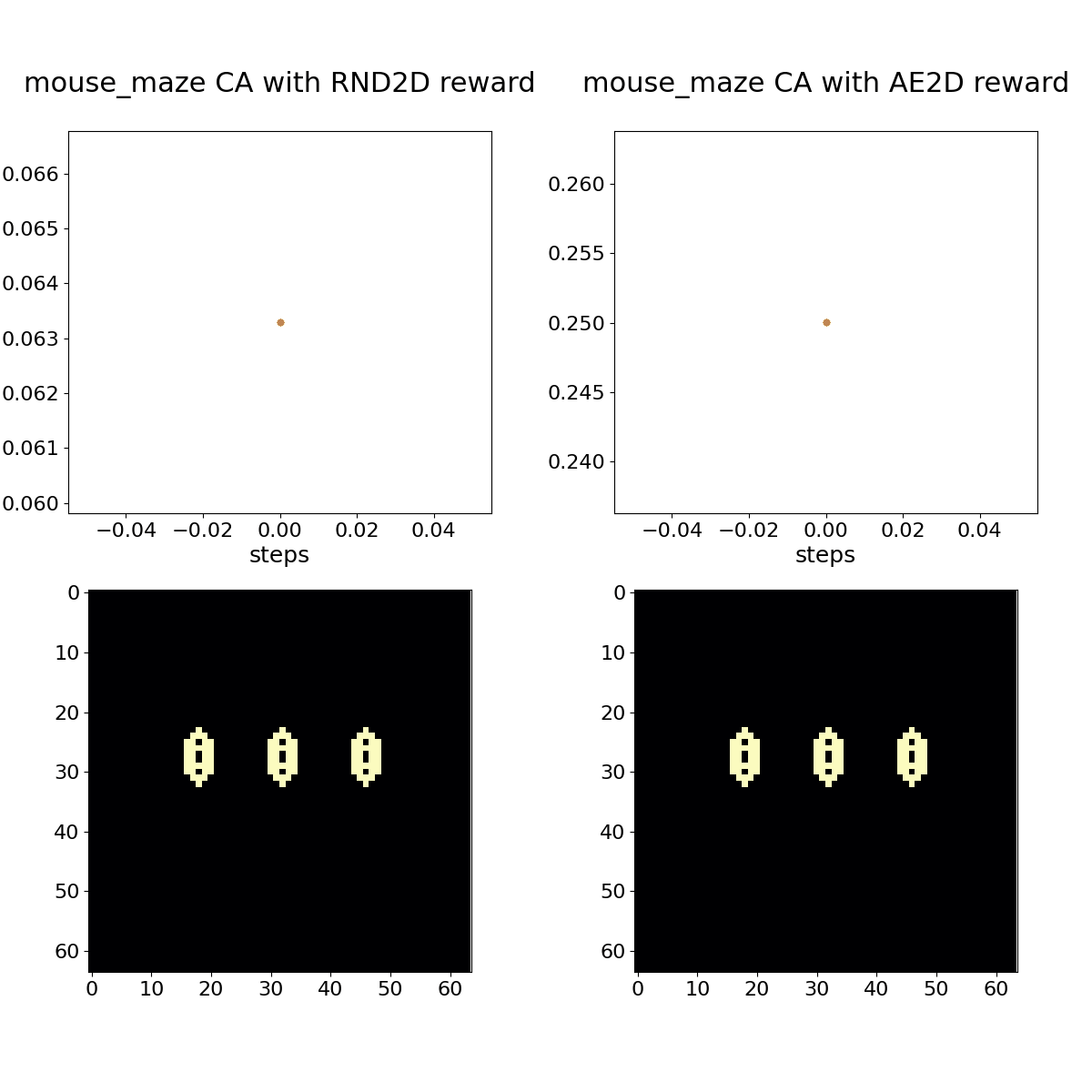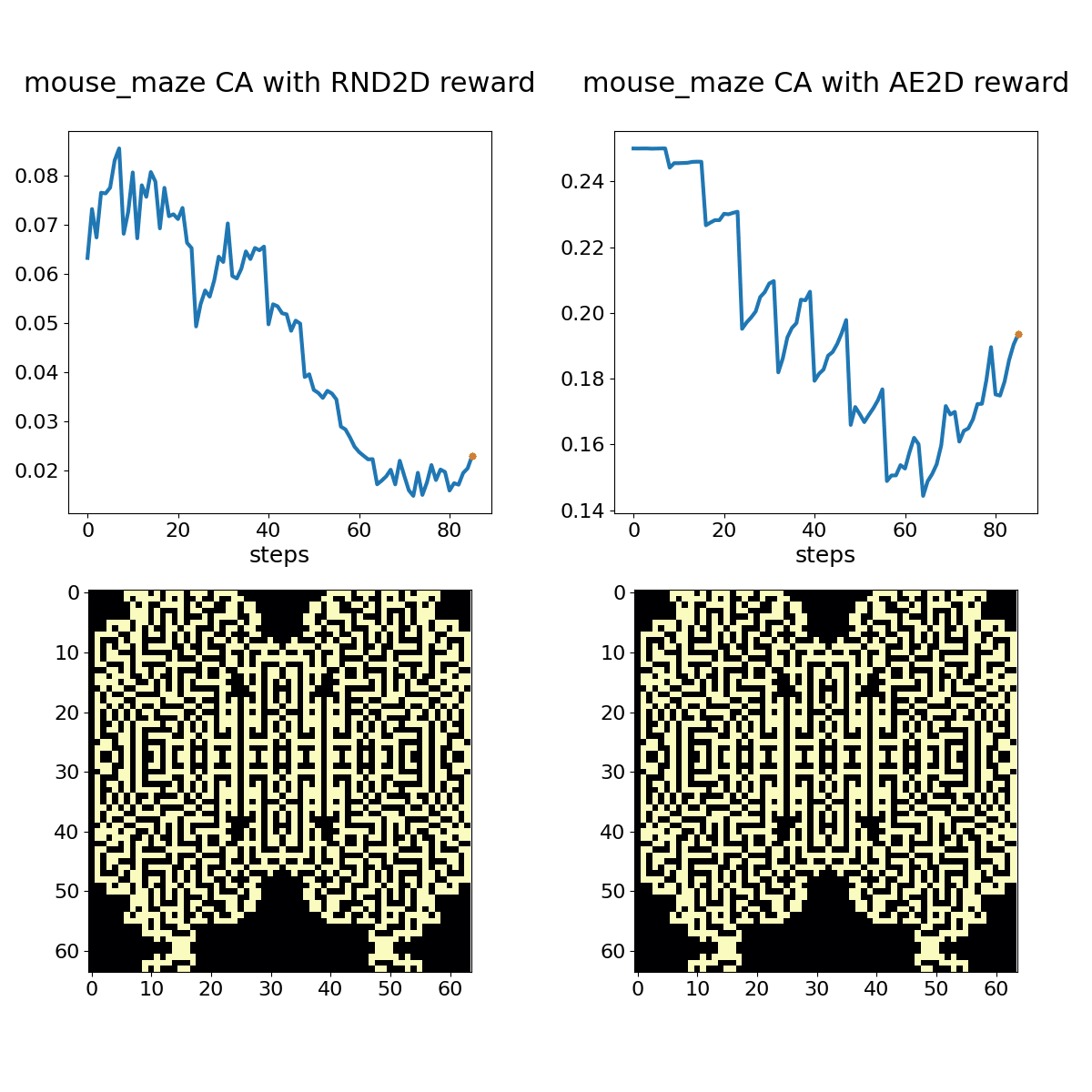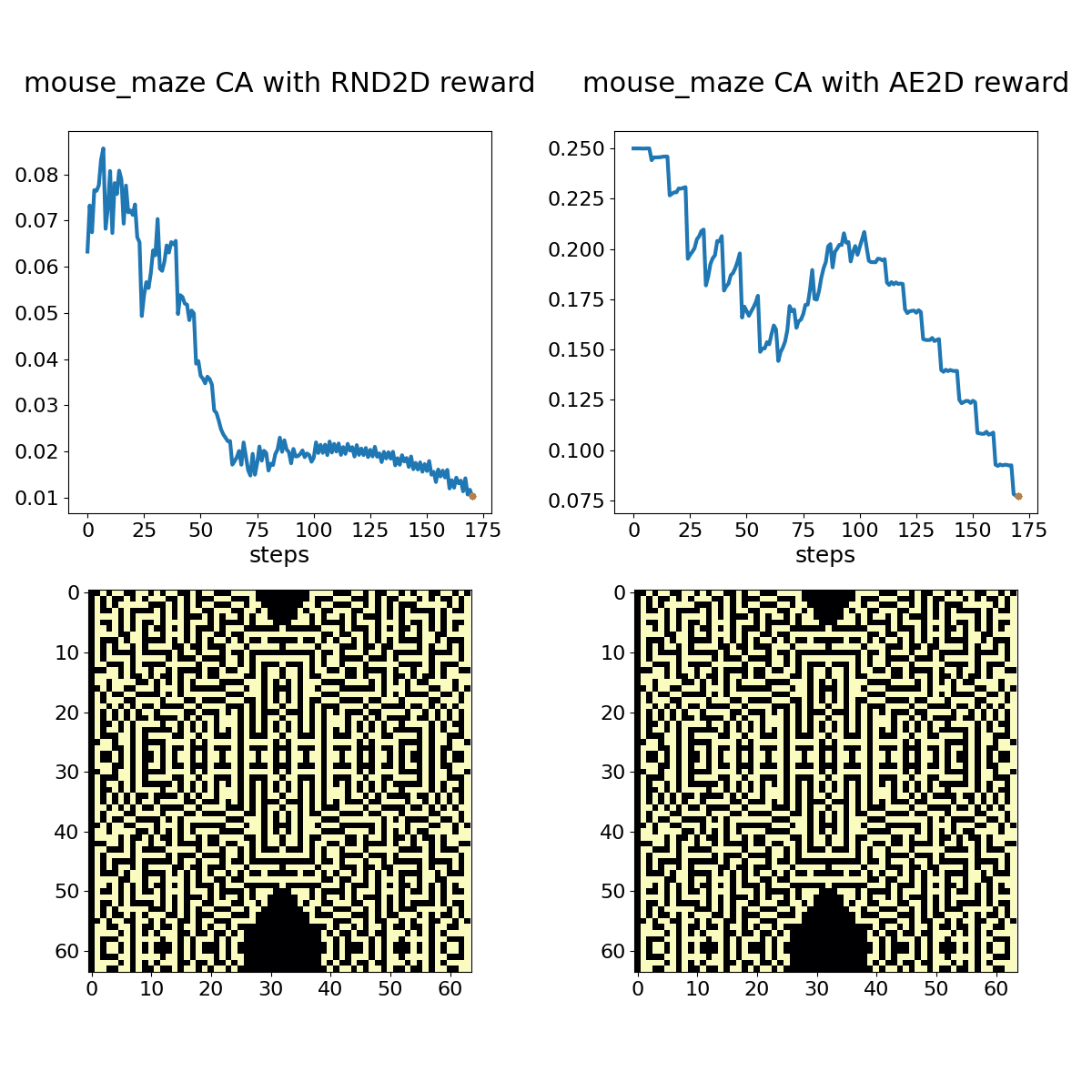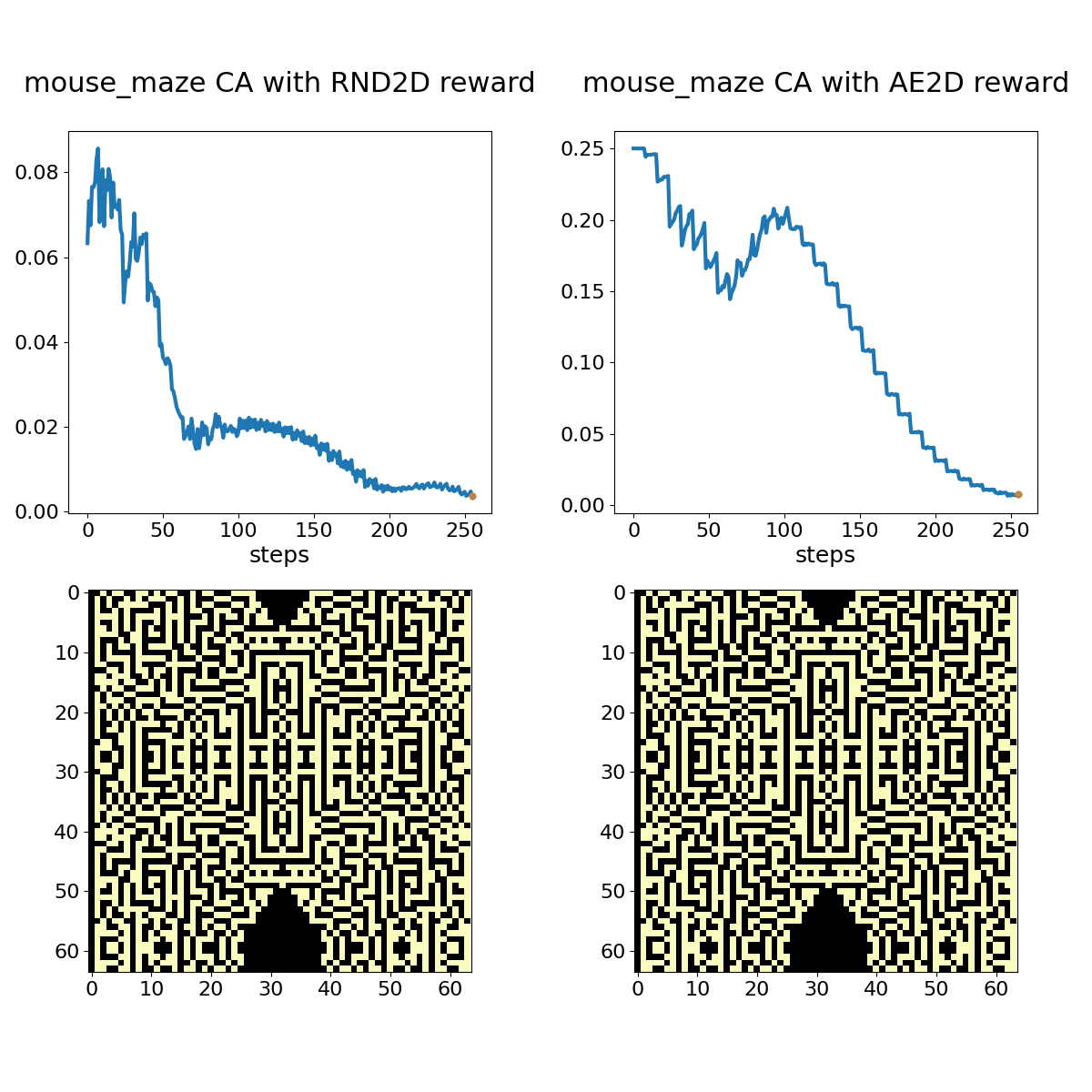
Mouse Maze shown with associated RND (left) and autoencoder loss (right) bonuses. The policy in this case is the same hand-coded oscillator protocol as before, but of course it doesn't generate an oscillator under this rule set.
While subtle differences characterize RND and AE loss bonus rewards, they both adapt to periodic or otherwise unsurprising patterns over the course of a few 100 time steps. A random policy that toggles 2% of cells in the action space at each time step provides a more stimulating sequence for these bonus objectives, but we can still observe adaptation with experience.
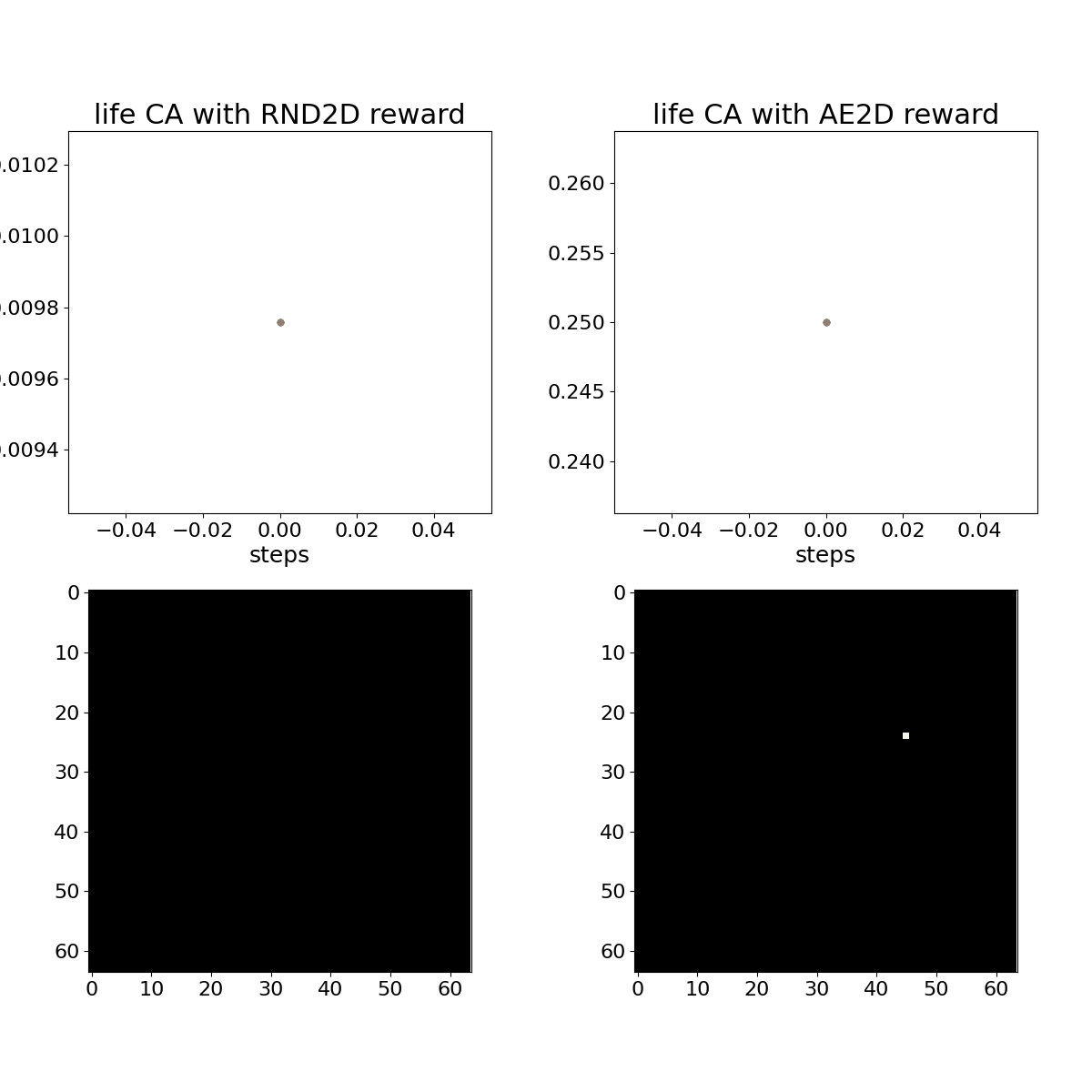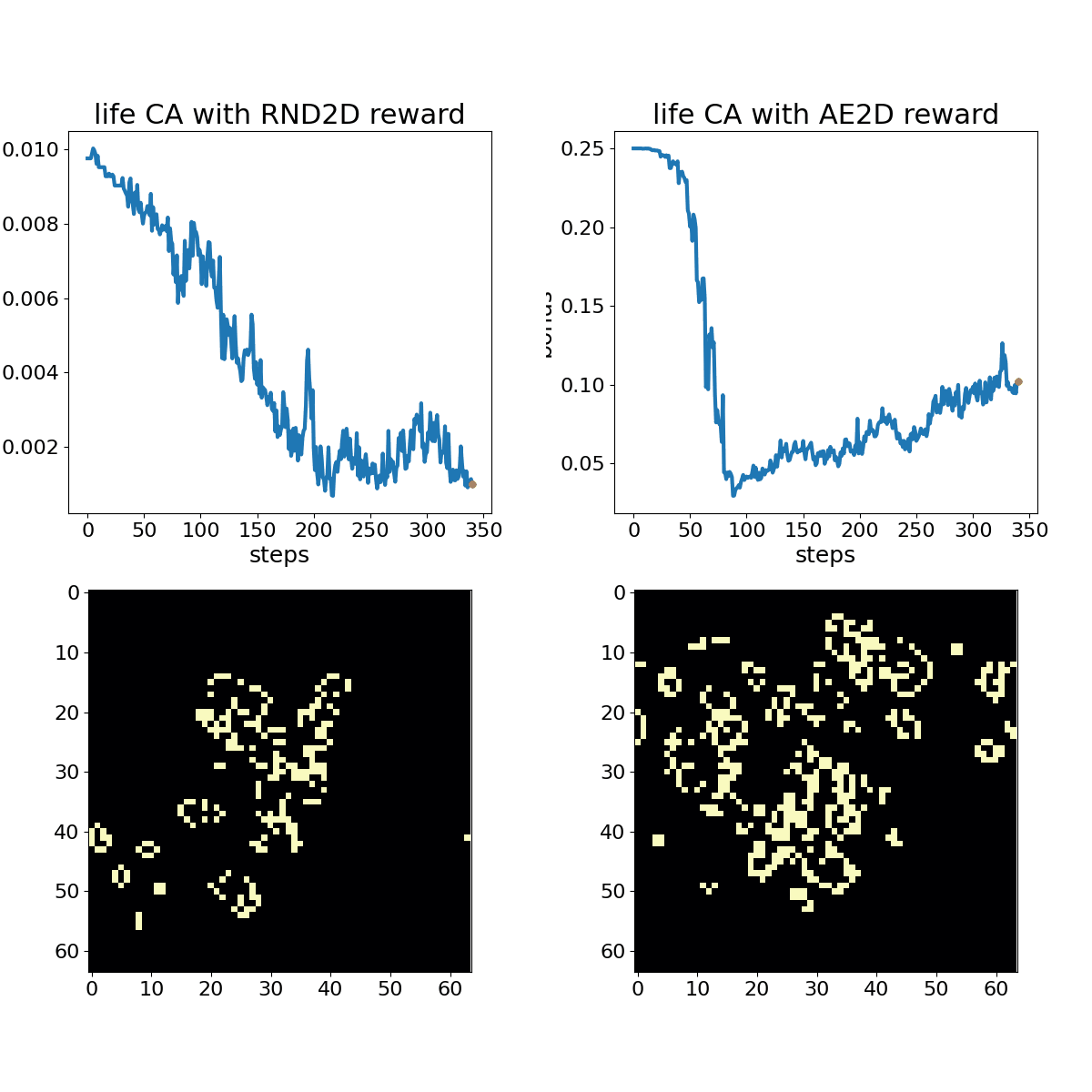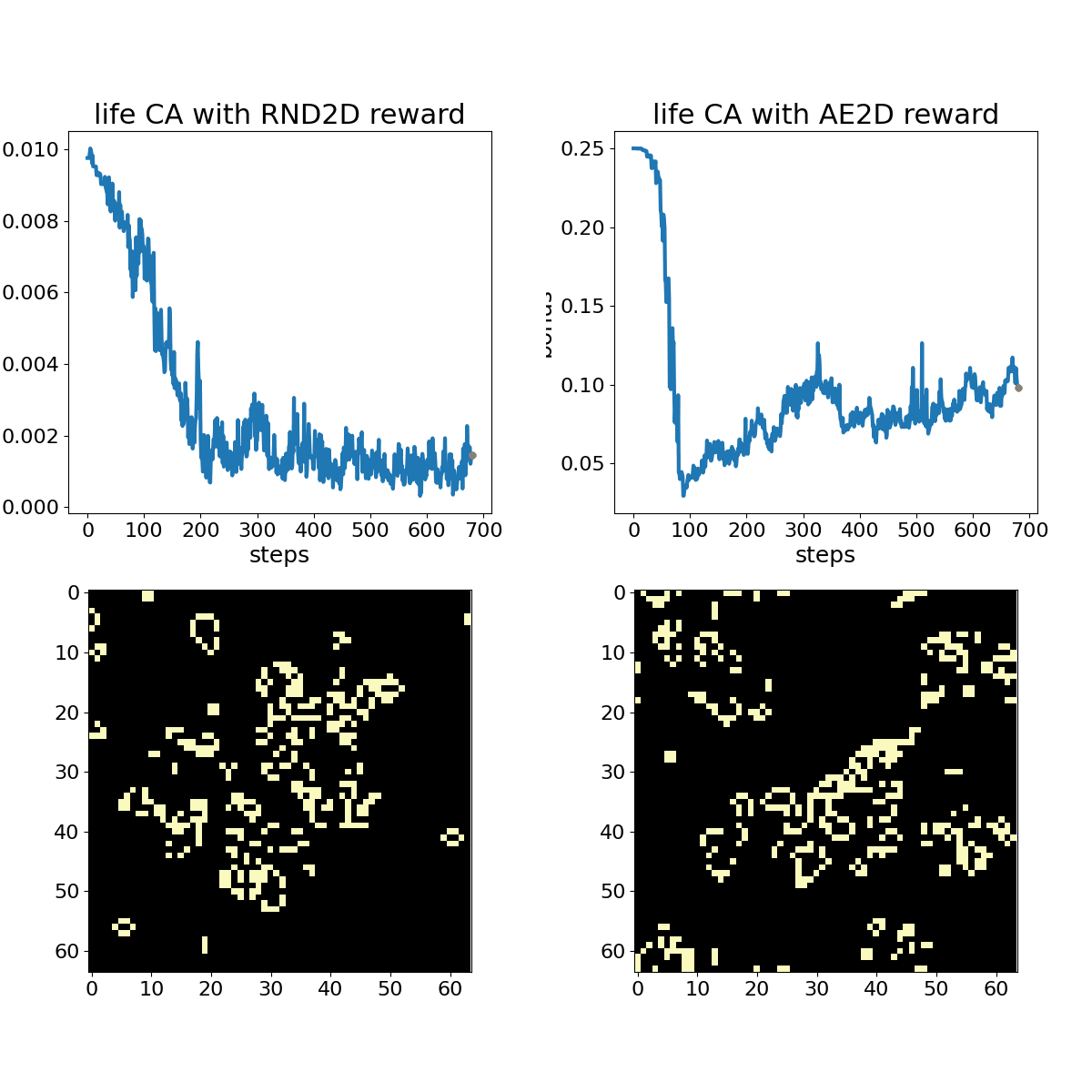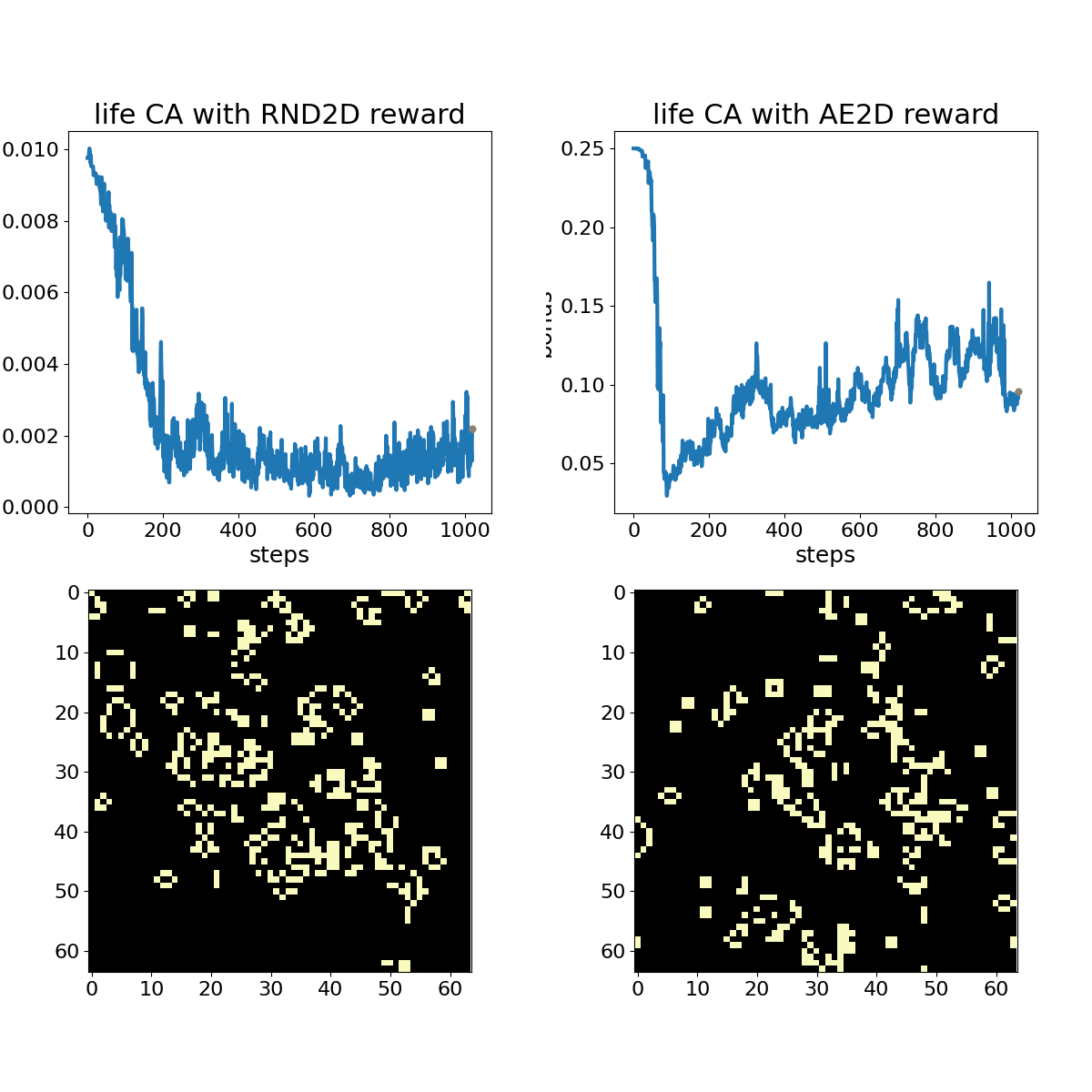
Conway's Game of Life shown with associated RND (left) and autoencoder loss (right) bonuses. The policy randomly toggles ~2% of the cells in the central 32x32 action space at each time step through the duration of the animation. This animation displays every 4th frame.
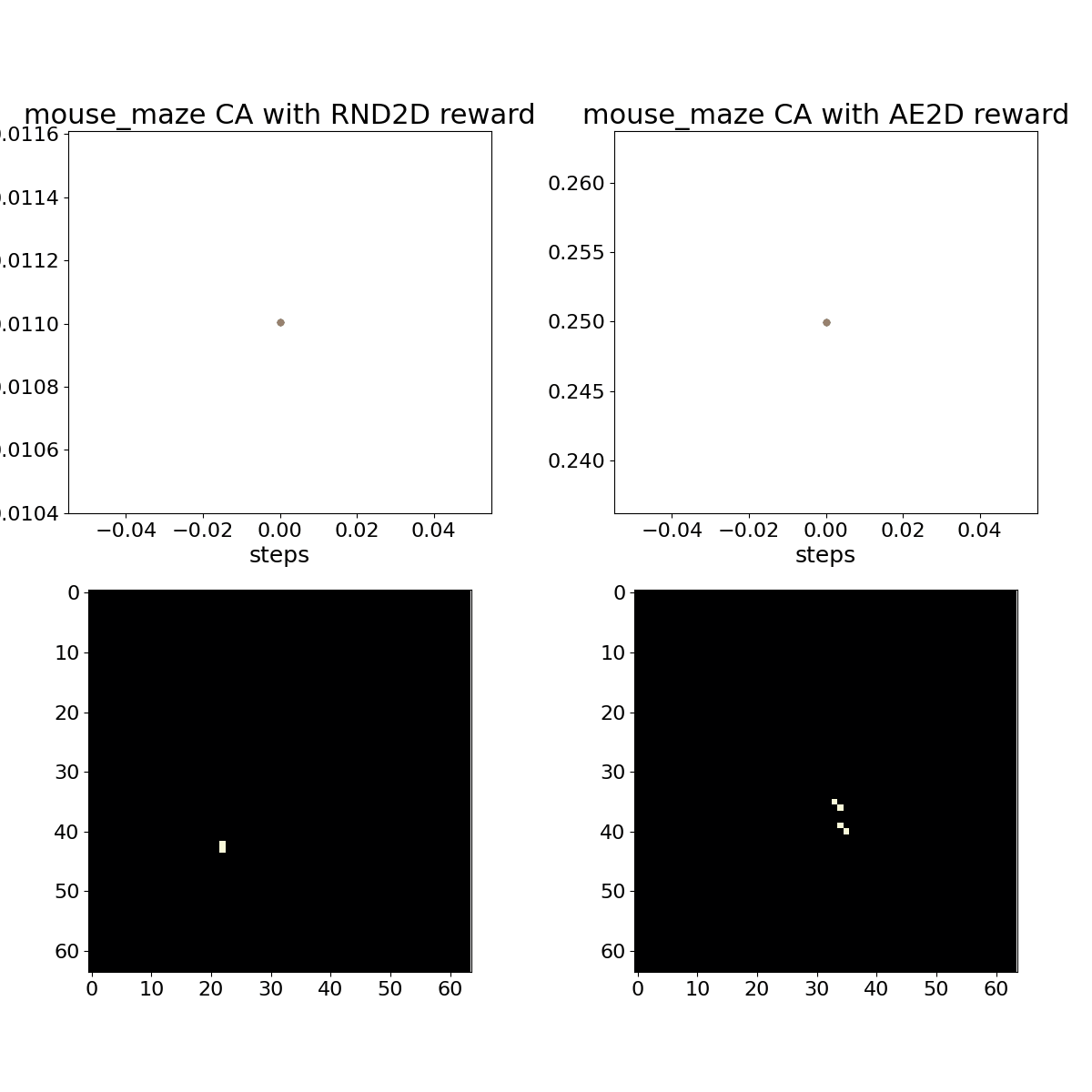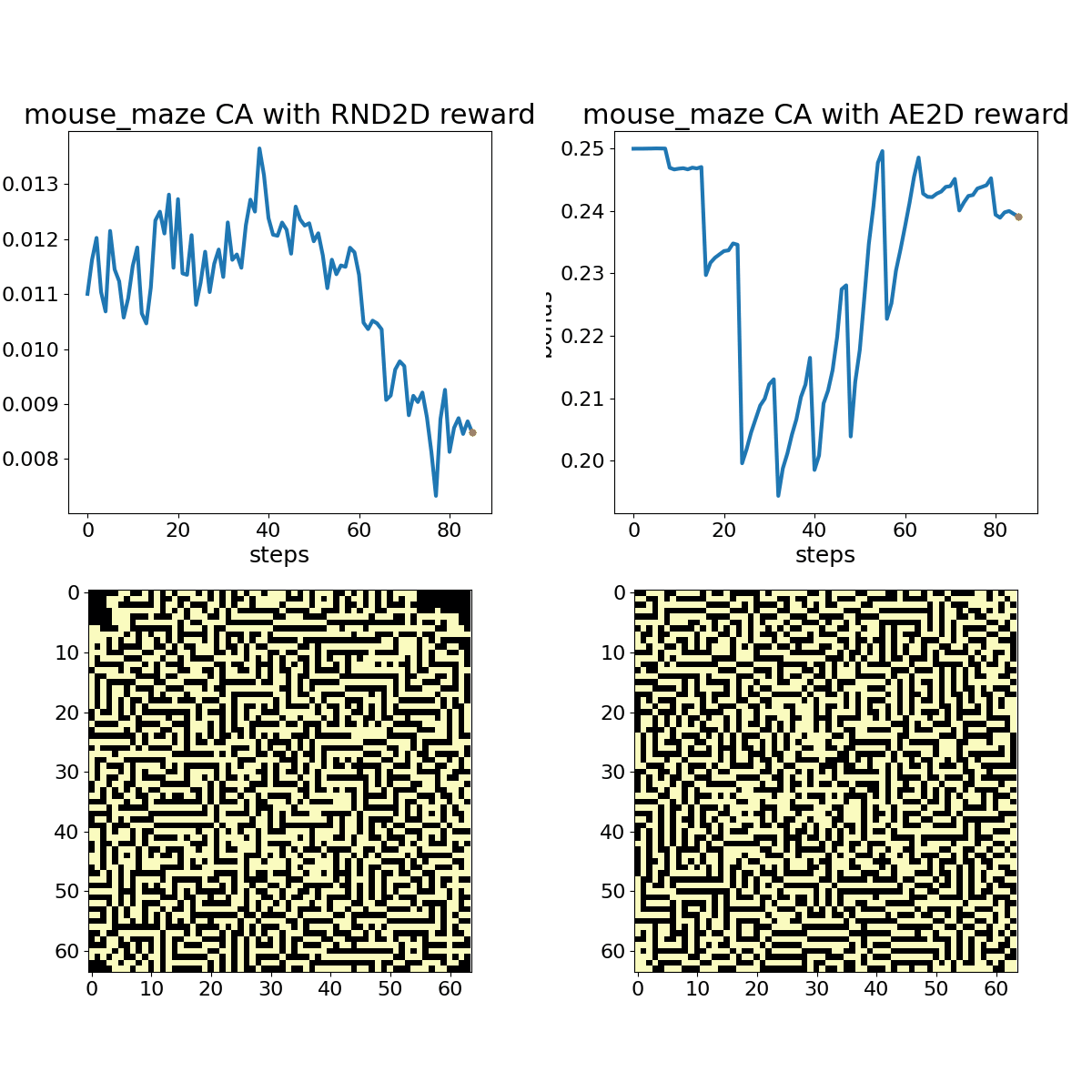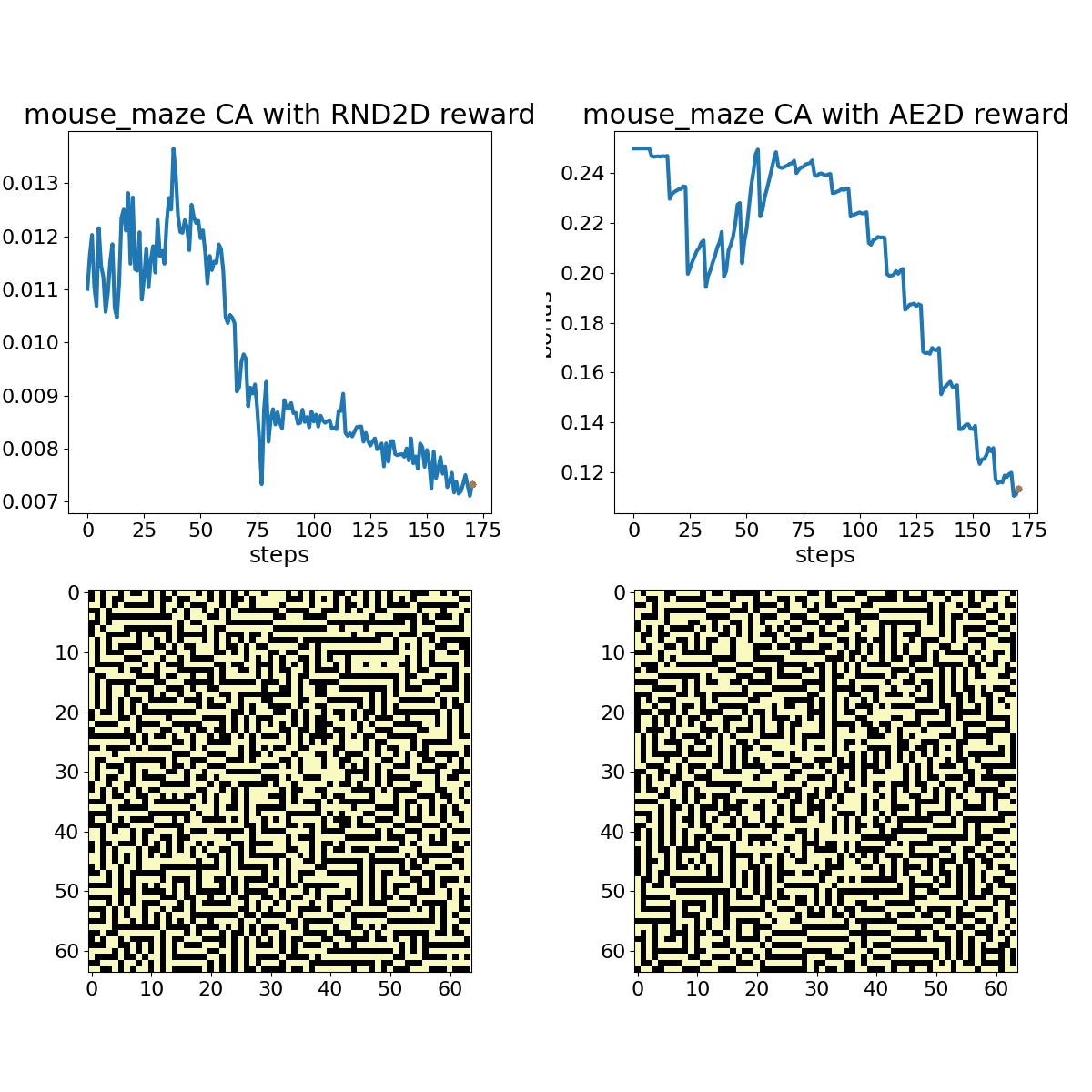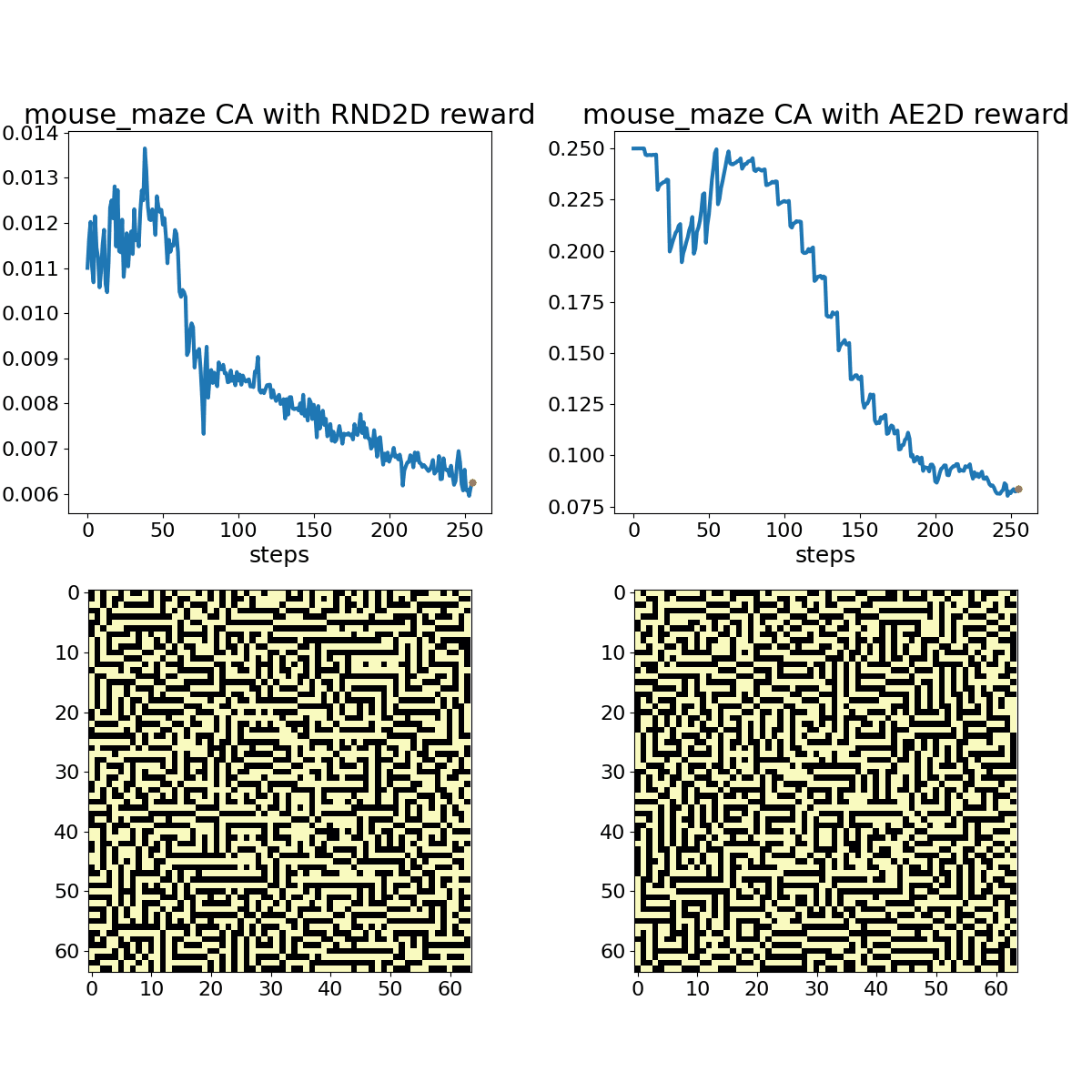
Mouse Maze shown with associated RND (left) and autoencoder loss (right) bonuses. The policy here is again a 2% random toggle policy, and the animation shows every frame.
The examples demonstrate that both exploration bonuses return higher values in the presence of complex chaos, without any consideration of human preferences for traits like parsimony and symmetry. Developing exploratory rewards that can induce learning machines to create beautiful and interesting machines in their own right remains a substantial challenge. Carle’s Game will encourage participants to come up with a flexible scheme for encouraging creative exploration across a number of different CA rules that may have vastly different characteristics. A more contrived example, shown below, demonstrates RND “getting bored” watching a Gosper Glider Gun, until gliders wrap around the universe and collide with the machine, creating exciting chaos.
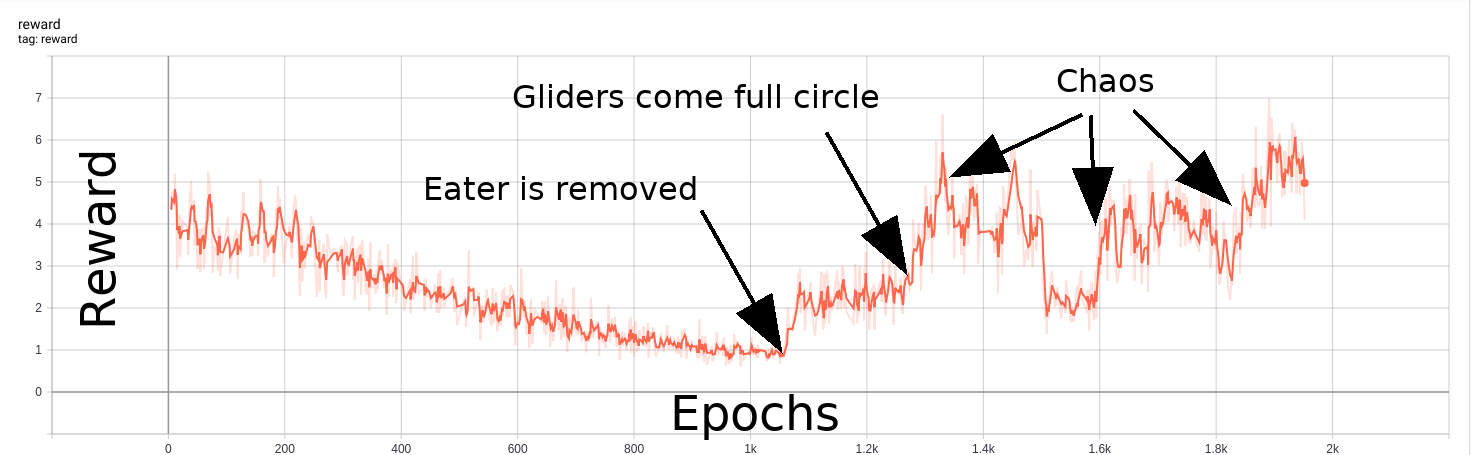
A Gosper Glider gun provides a diminishing RND reward over time, until gliders wrap around and cause chaos.
Flexibility
CARLE offers the flexibility to run cellular automata under Life-like rule sets. CA universes consist of 2D grids of cells with binary states of 1 or 0, typically termed “alive” or “dead.” The “birth” and “survival” rules defining a Life-like CA universe determine which cells spontaneously convert from dead to living states and which cells persist if they are already alive. These rules are based on the sum of states of adjacent cells in a Moore neighborhood. The sum of cell states in a 2D Moore neighborhood can take on 9 values from 0 to 8, therefore Life-like birth and survival rules occupy a space of possible rulesets with 2^9 * 2^9 or 262,144 possible configurations. Many of these rules create complex and chaotic evolution and the possibility for building beautiful machines (including Turing complete computers).
In addition to John Conway’s Game of Life, CARLE supports Life-like cellular automata including “High Life,” “Amoeba,” “Mouse Maze,” and many others. Arbitrary CA birth/survival (aka B/S) rules can be used for a high level of diversity. In addition, an official competition will use a different test environment that may use a different neighborhood and update rule formulation, although the observation and action spaces will remain the same 2D CA grid universe. This ensures a challenge that requires agents to be capable of creative exploration and meta-learning at test time.
Speed
CARLE implements Life-like cellular automata universes using the deep learning library PyTorch and takes advantage of environment vectorization. As a result, the environmnet can run at a rate of thousands of grid updates per second on a consumer laptop with 2 cores. A fast implementation lowers the barriers to making meaningful contributions to machine creativity and also increases the chances of actually developing creative agents in the first place.
| Vectorization Factor | Updates per Second (GoL) |
|---|---|
| 1 | 2239.77 |
| 2 | 3663.11 |
| 4 | 5618.96 |
| 8 | 7326.30 |
| 16 | 8779.06 |
| 32 | 9378.68 |
| 64 | 9657.42 |
| 128 | 9682.31 |
| 256 | 7581.44 |
| Vectorization Factor | Updates per Second w/ RND (GoL) |
|---|---|
| 1 | 348.59 |
| 2 | 616.23 |
| 4 | 959.89 |
| 8 | 1322.34 |
| 16 | 1710.91 |
| 32 | 1966.00 |
| 64 | 2096.01 |
| 128 | 1885.97 |
| 256 | 1814.00 |
Timeline
I’m currently looking for a conference to host CARLE as an official competition. The timeline for participation for any official competition will ultimately depend on the conference schedule, but here is a rough outline.
- 2021 March: Competition Launch
- 2021 March to May: Beta Round. In this round participants are encouraged to experiment with CARLE, raise issues, provide feedback, and make comments that help make CARLE and the associated challenge more interesting.
- 2021 May to Mid-July: Round 1 will have machine agents and their caretakers attempting to maximize open-ended metrics on 4 to 8 known CA rulesets. Metrics may include, but won’t be limited to, such accomplishments as duration of aperiodic dynamism without toggling cells in the action space, center of mass displacement speed without toggling cells, or human preferences.
- 2021 Late July: Final submissions due, test round begins. Machine agents (on their own this time) will be presented with previously unseen CA rules to see what they come up with.
- 2021 August: Final evaluations, fabulous prizes, prestige, presentation, etc.
Posts
-
Update 2021-04-05: Alpha release: support for run-length encoding, stacked reward wrappers, and more.
-
Update 2021-02-14: Fix cellular birth logic, blog post about evaluation in open-endedness.
-
Update 2021-01-17: New exploration bonus and RND bug-fixes
subscribe via RSS